Publications
2026
-
 Understanding BTB Tag SizingRoman K. Brunner, and Rakesh KumarIn IEEE International Symposium on Performance Analysis of Systems and Software, Apr 2026
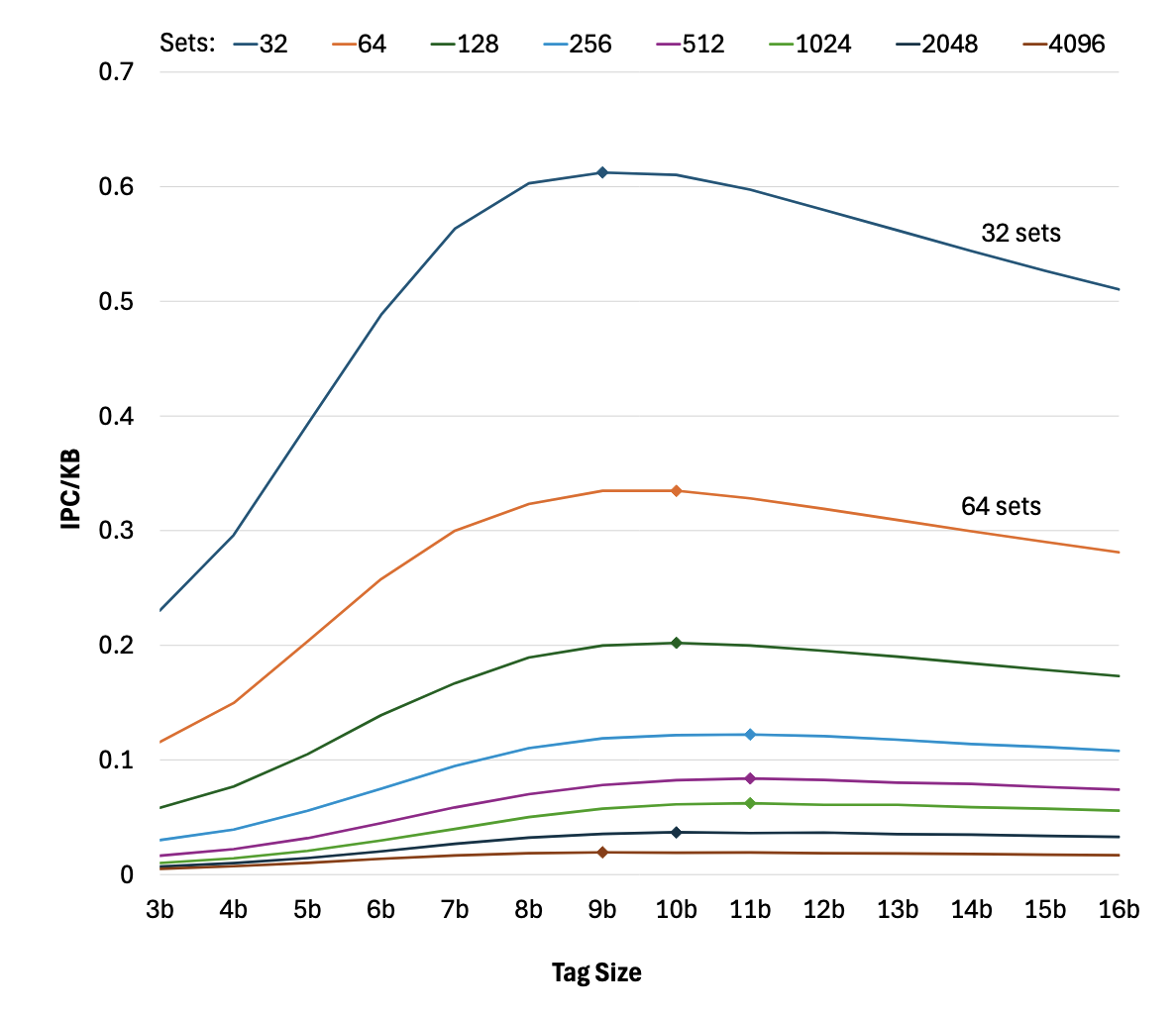
Understanding BTB Tag SizingRoman K. Brunner, and Rakesh KumarIn IEEE International Symposium on Performance Analysis of Systems and Software, Apr 2026The large branch footprints of contemporary applications easily overwhelm the capacity of Branch target buffers (BTBs). Therefore, to avoid frequent BTB misses and their associated performance penalties, commercial processors feature massive BTBs that require hundreds of KBs to multi-MB storage budgets. Furthermore, storage requirements are increasing at an alarming rate, a trend that is certainly not sustainable. As the bulk of BTB storage budget goes towards storing branch targets, researchers have recently proposed storage-efficient schemes for target representation. The state-of-the-art schemes are so effective that branch targets no longer dominate the BTB storage requirements, rather, the tags do. However, there has not been any study on understanding the implications of tag size on performance, storage, and aliasing. This work bridges this gap by performing a comprehensive study of how and why tag size requirements vary for performance- and storage-efficiency-oriented BTB designs across different BTB capacities. The results of the study help BTB designers understand where in BTB to invest any additional storage budget that becomes available in next processor generations. The key findings of this study include: 1) moderately sized BTBs (2K to 8K entries) require larger tags than small (256-entry) and large (32K entry) BTBs, 2) increasing the number of ways in the BTB also requires larger tags to fully realize the benefits of the additional ways, and 3) a storage-efficient BTB design reduces tag storage requirements by up to 21% over a performance-oriented BTB design.
-
 Driving the Core Frontend with LiteBTBRoman K. Brunner, and Rakesh KumarIEEE Computer Architecture Letters, Feb 2026
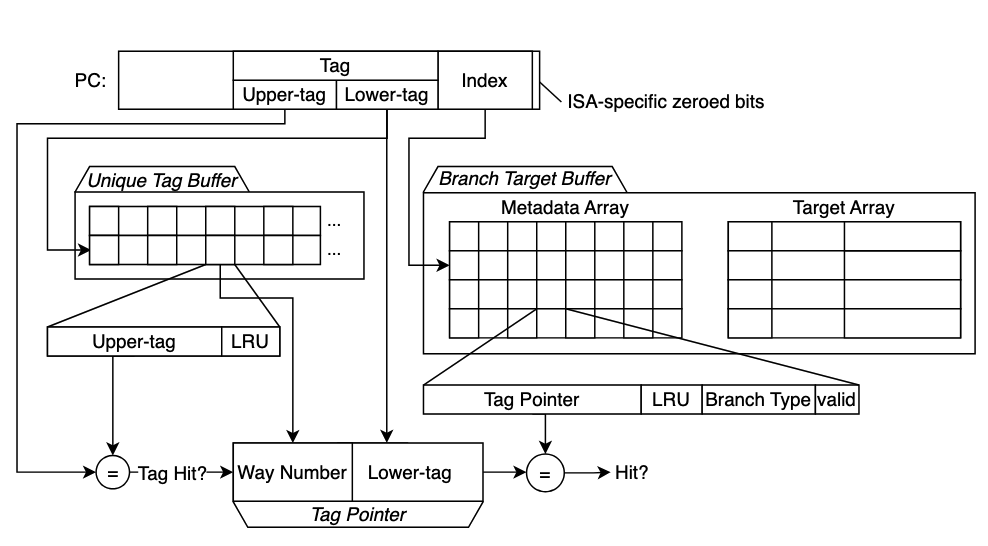
Driving the Core Frontend with LiteBTBRoman K. Brunner, and Rakesh KumarIEEE Computer Architecture Letters, Feb 2026Branch target buffer (BTB) is a central component of high performance core front-ends as it not only steers instruction fetch by uncovering upcoming control flow but also enables highly effective fetch-directed instruction prefetching. However, the massive instruction footprints of modern server applications far exceed the capacities of moderately sized BTBs, resulting in frequent misses that inevitably hurt performance. While commercial CPUs deploy large BTBs to mitigate this problem, they incur high storage and area overheads. Prior efforts to reduce BTB storage have primarily targeted branch targets, which has proven highly effective — so much that the tag storage now dominates the BTB storage budget. We make a key observation that BTBs exhibit a large degree of tag redundancy, i.e. only a small fraction of entries contain unique tags, and this fraction falls sharply as BTB capacity grows. Leveraging this insight, we propose LiteBTB, which employs a dedicated hardware structure to store unique tags only once and replaces per-entry tags in BTB with compact tag pointers. To avoid latency overheads, LiteBTB accesses the tag storage and BTB in parallel. Our evaluation shows that LiteBTB reduces storage by up to 13.1% compared to the state-of-the-art BTB design, called BTB-X, while maintaining equivalent performance. Alternatively, with the same storage budget, LiteBTB accommodates up to 1.125× more branches, yielding up to 2.7% performance improvement.


2024
-
 Weeding out Frontend Stalls with Uneven Block Size Instruction CacheRoman K. Brunner, and Rakesh KumarIn 57th IEEE/ACM International Symposium on Microarchitecture, Feb 2024
Weeding out Frontend Stalls with Uneven Block Size Instruction CacheRoman K. Brunner, and Rakesh KumarIn 57th IEEE/ACM International Symposium on Microarchitecture, Feb 2024The core front-end remains a critical bottleneck in modern server workloads owing to their multi-MB instruction footprints stemming from deep software stacks. Prior work has mainly investigated instruction prefetching and cache replacement policies to mitigate this bottleneck. In this work, we take an orthogonal approach and analyze instruction cache storage efficiency. Our analysis shows that, on average, about 60% of the bytes in a cache block are never accessed before the block is evicted from the instruction cache. This represents a huge storage inefficiency that more than halves the effective cache capacity. We observe that this inefficiency is caused by the fixed cache block sizes which are unable to accommodate the varying spatial locality inherent in the instruction stream. To mitigate this inefficiency, we propose Uneven Block Size (UBS) instruction cache, which supports different cache block sizes in a cache set. Our evaluation shows that UBS cache improves the storage efficiency by 32 percentage points over the baseline instruction cache. Further, by supporting uneven block sizes, UBS cache accommodates more than twice the number of blocks than a conventional cache within a given storage budget. Overall, the additional blocks combined with the better storage efficiency result in UBS cache approaching the performance of a 64KB conventional cache on a set of server workloads while requiring a storage budget similar to a 32KB conventional cache.

2020
-
 Formal Verification and Modelling of the Gen-Z SpecificationRoman K. BrunnerETH Zurich, Feb 2020
Formal Verification and Modelling of the Gen-Z SpecificationRoman K. BrunnerETH Zurich, Feb 2020In this thesis, I will explore different approaches to modelling the Gen-Z specifications [60]. The Gen-Z interconnect enables new system topologies, such as memory-centric systems, based on the disaggregated system design, leveraging network based system interconnects. The flexibility of Gen-Z concerning system design and topologies makes it attractive to industry and research alike. We have the rare opportunity to influence the design of Gen-Z in an early stage, as only recently the first final specification for Gen-Z has been released, and as of today no commercial hardware is available. This makes it interesting to formally model the Gen-Z specification in order to enable proofs of the different properties provided by the Gen-Z interconnect, as currently changes can be easily implemented. As the abstraction level of the Gen-Z specification ranges from the physical layer up to the application layer, including abstract security protocols, the types of proofs, the requirements for a formal specification and modelling languages, as well as the toolchain to implement such a model, vary significantly across the different layers. I evaluated different approaches to modelling Gen-Z by comparing them with an newly defined ideal for formal languages and their toolchain. To evaluate the different modelling approaches, I wrote several proofs-of-concept models and tools. I also applied these models to prove different properties of the security protocols of Gen-Z. Using the results of the proofs, I was able to identify two protocols within Gen-Z that do not provide additional guarantees and therefore could be removed and additional assumptions that are required in order for the security protocols to guarantee the desired properties.

2018
-
 Structure and content of the visible DarknetGeorgia Avarikioti, Roman K. Brunner, Aggelos Kiayias, and 2 more authorsarXiv preprint arXiv:1811.01348, Feb 2018
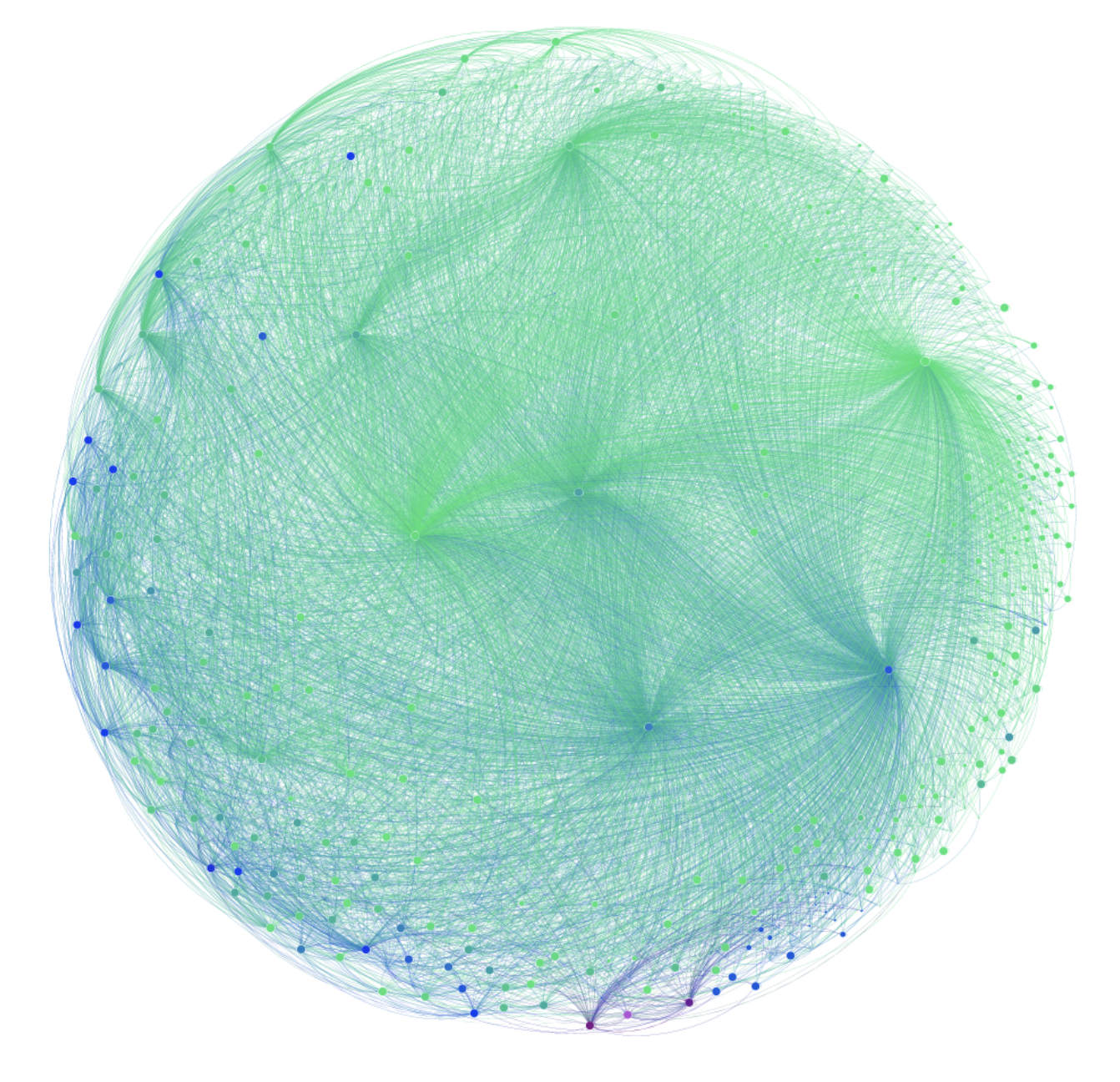
Structure and content of the visible DarknetGeorgia Avarikioti, Roman K. Brunner, Aggelos Kiayias, and 2 more authorsarXiv preprint arXiv:1811.01348, Feb 2018In this paper, we analyze the topology and the content found on the "darknet", the set of websites accessible via Tor. We created a darknet spider and crawled the darknet starting from a bootstrap list by recursively following links. We explored the whole connected component of more than 34,000 hidden services, of which we found 10,000 to be online. Contrary to folklore belief, the visible part of the darknet is surprisingly well-connected through hub websites such as wikis and forums. We performed a comprehensive categorization of the content using supervised machine learning. We observe that about half of the visible dark web content is related to apparently licit activities based on our classifier. A significant amount of content pertains to software repositories, blogs, and activism-related websites. Among unlawful hidden services, most pertain to fraudulent websites, services selling counterfeit goods, and drug markets.
